Can Amazon SageMaker Unified Studio deliver on the Lakehouse + AI/ML vision?


The first thought that came to mind when I heard Amazon SageMaker Unified Studio announced at re:Invent 2024 was that this is it. This is how AWS competes with Databricks, Snowflake and Azure Fabric. It’s not EMR or Glue or even Redshift, it’s SageMaker.
Original SageMaker did all of the data science stuff. It let you prepare data, do feature engineering, train and test models, catalog assets and serve models for real-time inference. It is honestly a powerhouse for ML workloads. But what users missed was the ability to plug into the rest of the data and analytics estate. It wasn’t very simple for users to discover, collaborate and query datasets available for analytics users in Redshift or the data lake on Amazon S3.
The idea of SageMaker Unified Studio bringing together analytics and AI made a ton of sense. That’s what users love about Databricks and Snowflake and Fabric. You don’t need to jump from tool to tool, it’s all in one place, easy to find and use.
And then AWS presented this slide (also on the SageMaker homepage):
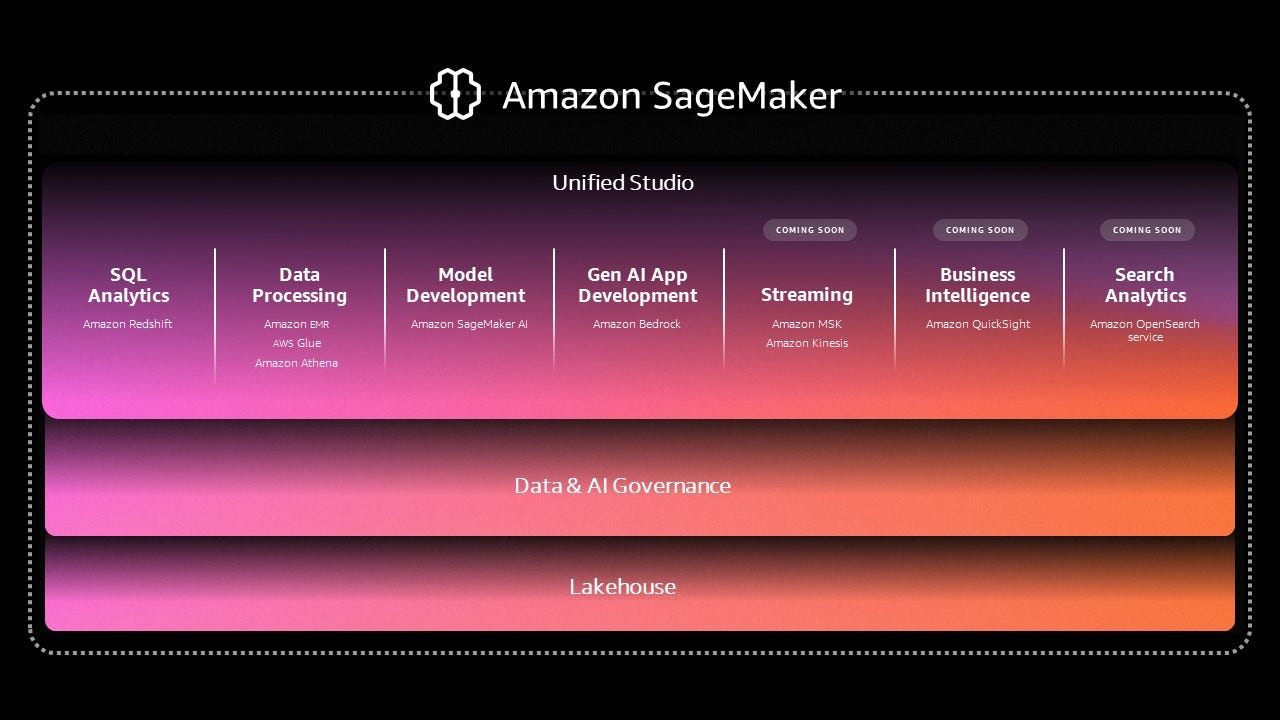
Analytics and AI applications on top of a governed Lakehouse. A powerful product strategy, that if executed correctly can catapult AWS to a market leader, up there with Databricks and Snowflake.
What is SageMaker Unified Studio
SQL Analytics - Amazon Redshift and Athena. Data Processing - Amazon EMR and Glue. Streaming - Amazon Kinesis and MSK. Search Analytics - Amazon OpenSearch. Model Development - Amazon SageMaker AI. Gen AI Development - Amazon Bedrock.
Wait a minute, this isn’t a tool for modern data users wanting to build data and AI products. This is a collection of AWS analytics products clumped together under a single “Unified Studio” brand. Ummm…this is not what got me excited.
The Studio experience is not new to AWS. Over the last 2-3 years, they attempted to consolidate capabilities by adopting a studio experience that unifies many of the functions of a service into a new UI, sometimes within the AWS console and sometimes outside of it. EMR Studio, Glue Studio, and to some degree the UI redesign of Redshift. Studio tries to solve for their always-frustrating UI/UX, improve feature discoverability and simplify the getting started flow for new and returning users.
SageMaker Unified Studio is a bold attempt at Studiofying a whole bunch of services in one shot, bypassing the differences and challenges with each service and attempting to streamline user experience with only UI.
As a product person, I can tell you from experience, you don’t solve technical product problems, differences and nuances with UI. It only amplifies a user’s pain and frustration. The gap between expectation and reality is big, very big.
It’s only preview, it will get better
It won’t.
The mistake, in my opinion, that AWS made is they tried to combine their analytics services under a single UI and weave them together with clever UX. They did this by placing services into categories based on the use case they are designed to solve. SQL Analytics includes Redshift and Athena. Data Processing includes EMR, Glue and Athena. And so on. They weaved these services together through common catalog and storage layers. From a product interoperability perspective this makes a lot of sense.
However, from a user solving business problems and delivering on key use cases, this simply doesn’t work, well.
As more service-specific capabilities are exposed in the Unified Studio UI, it becomes more difficult to weave them into the UX without creating confusion, duplication and complicating setup and configuration.
At the end of the day, users don’t care about the different AWS services. They care about leveraging capabilities on top of a range of compute resources, with little to no configuration and management overhead. For example, I do this fairly often, I want to find a dataset, query it, extract a portion of it and train a prediction model on it. Whether I use Athena or Redshift or Glue or EMR to do this doesn’t add any value. These are just compute resources with unique strengths and weaknesses. As an end user, I don’t know or care, I want a compute resource that can do the job and I expect SageMaker Unified Studio to recommend one, not make me choose. Sometimes abundance of choice is not desirable.
Even Databricks and Snowflake are starting to run into this UX challenge, but at least they’re not trying to shove 10+ different services down your throat.
Execution will make or break SageMaker
This is where things really started to fall apart for me.
Whether AWS’s collection of services under a unified studio strategy is wise or not is up for debate, however, whichever approach you take, executing on it properly will determine your success.
SageMaker Lakehouse
The idea of a central lakehouse with shared storage and shared data catalog is a brilliant way to both create a scalable lake and to enable access from a number of tools within the SageMaker ecosystem.
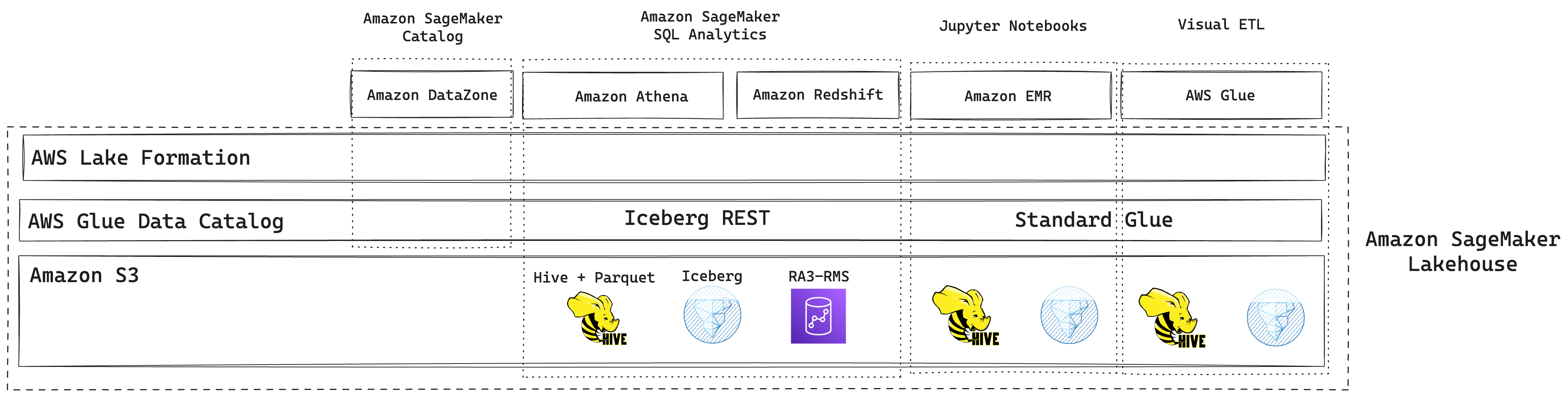
Data catalog(s)
To unify the Lakehouse AWS released new capability that I’ve been waiting for a long time - Iceberg REST-spec compliant endpoint for Glue Data Catalog. This means that now any Iceberg-compatible engine can connect to GDC and query data without a custom client (like required by S3 Tables and Standard GDC).
With the new catalog endpoint, users have the option to store their data in three ways:
Standard Hive compatible tables with metadata stored in the catalog and data in Parquet or another supported format on S3
Iceberg tables with data in Parquet on S3.
Redshift Managed Storage tables where the metadata is in the catalog and data is stored in the RA3 instance SSDs attached to your Redshift cluster. Data in RA3 is tiered to S3 based on different factors.
WHY WHY WHY? Why can’t you just default everything to Iceberg and give me an “advanced” option to choose other formats? Choice is great, but I don’t want to constantly think about it. Iceberg is a fantastic default, just use it.
* Note: from my testing, it doesn’t seem that EMR or Glue ETL within SM Unified Studio (SM-US) are using the catalog’s REST endpoint by default, but rather the traditional APIs. I could be wrong here but hopefully AWS will converge on the REST endpoint for everything.
Because the REST endpoint is backed by GDC, these resources are automatically available to other systems like Lake Formation and DataZone.
In addition to Lakehouse catalog, SM Lakehouse also exposes a Redshift catalog (backed by GDC) with data stored in it’s own RMS storage, that only Athena (for now) can read, but only Redshift can write. Because these catalog are shared, datasets show up in multiple places. Confused yet?
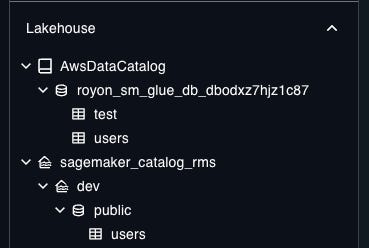
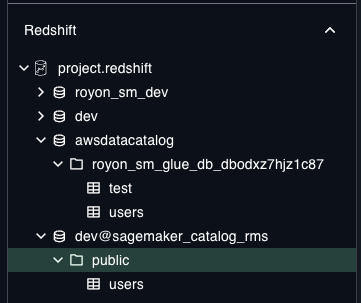
You’re probably thinking, what if I already have data in Redshift and I want to see it here? Well great, but you can’t. When creating the SM project, it creates a catalog that’s isolated from your other stuff, so you don’t actually see your other tables, only what is created inside your SM project.
Ok so that’s 2 different catalogs you need to deal with. But wait, there is actually a 3rd. The third one is a business catalog provided by DataZone called SageMaker Catalog. This catalog is used to register assets, document them, publish them for others to use and subscribe to table change notifications. However, this SM Catalog is not connected to Lakehouse catalog, forcing you to manually publish tables for others to find and use. It would be helpful to make this process more streamlined, instead of a disconnected experience that I had to find out about the hard way - clicking all around to see what stuff does.
If you want to be picky, you can actually count Lake Formation as a 4th catalog 🤯
Fine-grained access controls
Lake Formation serves as the fine-grain access control (FGAC) engine for SM Lakehouse. In addition, LF is where you can create and register new catalogs - not visible in the GDC console, only via CLI/SDK. Before you can actually see the catalog tho, you need to give your user/role the proper LF permissions. Below screenshot shows how you grant “Describe” permission at the catalog level (no DB or tables selected) to your IAM principal. I also granted “Create databases” so I can do that outside of SM Lakehouse.

Lake Formation is actually pretty useful once you understand how it works and what permissions you need to set and where. Also remember that any catalog resources you create in SM Unified Studio are permissioned to the user who created the SM project. If you want to access those resources with another user or role, you’ll need go through the entire process of assigning them permissions in Lake Formation.
Query engines
In the SQL Query experience, when you select a table from the Lakehouse catalog (top section in the left-side nav) you are given an option to query it using Athena or Redshift. If you select a table from the Redshift catalog (second section) you can only query it via Redshift. Makes technical sense, but why? Why do I need to choose an engine, all I want to do is query my table. Again, give me the best default experience and if I want something else, I’ll choose to activate it outside of the main workflow.
Even more confusing, for the Lakehouse in particular, is that each engine, Athena or Redshift has different syntax, data types, functions, and behave very differently. As a user, I don’t want to deal with this cognitive load all the time. A good default here can make life soooo much simpler for users.
The experience outside of SageMaker Unified Studio is much more complex. Given that everything has been scoped to the SM federated user and the project buckets, querying tables, updating rows and interacting with data requires more fiddling and tuning then I would have hoped 😔
One nice feature in Athena is a nifty switcher that allows you to go between Athena workgroups and DataZone environments which makes discovering published datasets simpler. Kudos to the Athena team for thinking about this.
*Do remember to keep product names straight…Since SM-US uses DataZone behind the scenes to publish and share catalog resources, it is exposed outside of SM as DataZone, not SageMaker, so make sure you name your resources with descriptive names or you’re in for a lot of wasted time.

The experience is a bit smoother when using Redshift (independent of SM) to query the tables, especially for those created in the RMS catalog. For those created in the Lakehouse catalog you will need to give the Redshift logged in user permissions in Lake Formation to access these tables - not too hard, but something to keep in mind.
Visual ETL
Trying to build a visual ETL workflow, I quickly ran into a connectivity issue. Without any warning, trying to add a Lakehouse source I simply could find any tables.

Same thing with a Redshift connections.
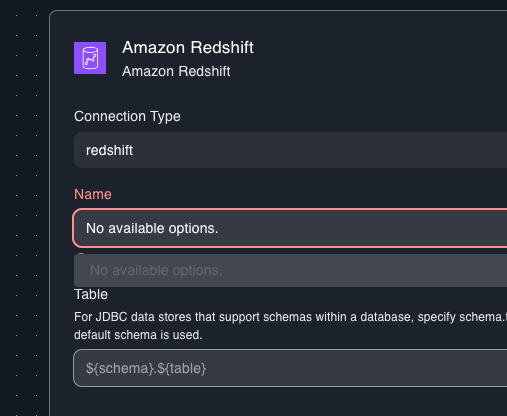
Lets spin up a notebook and try to access data from there. 5+ minutes after creating a new ML training project…
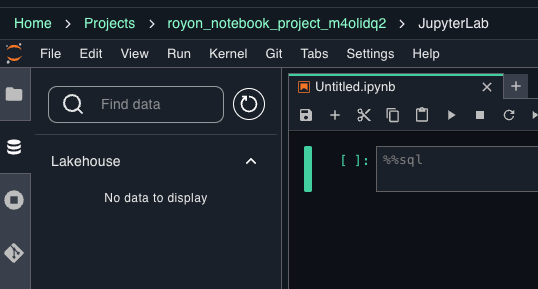
I give up.
From SageMaker Lakehouse standpoint, the execution is lacking. I understand it’s still preview (as of Dec 2024), but even the basic things require a lot of fiddling to get working. Too much focus has been spent on including and highlighting the different products and little attention was paid to helping users get their job done. I didn’t even explain Jupyter notebooks, Airflow DAGs and training models on Lakehouse tables.
Maybe Amazon Q can magically make it all work for me? Wishful thinking 🤦🏻♂️
SageMaker projects
I like the idea of projects to divide use cases and resources. However, creating SM projects feel very heavy. It takes a long time to set up and creates a bunch of stuff I’m not even aware of, let alone be able to track associated costs.
Projects are created around common use cases like SQL queries, ETL or model training. Nice, but why? If I want to collect some data, prep it and then jump into a notebook to test some models, I’d have to switch projects. If my data isn’t quite right, I’ll need to switch again. Why make it so complicated? For example, if you’re in a SQL Analytics project and want to “build” using Jupyter Notebooks, you get this:
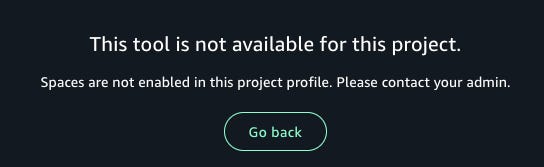
So you have to go back, create a new “ML and GenAI model development” project, wait a bunch of time, switch into it and use the notebook.
What I would love, is to create a use case based project where I’m able to pull in tools to do different aspects of my projects. Select table to query. Do some prep and write it into a new table. Open a Notebook, read the table and load it into a model training function. Once done, orchestrate it all to run once a day. Then from here, click “publish model” and boom it’s hosted with an inference endpoint ready to use. I want this without having to jump from project to project, relearn where stuff is, what it was called and any differences in syntax between tools.
Costs
Cost of SageMaker Unified Studio is broken out into the costs of the individual services and their paid capabilities. There are a lot of moving parts to keep track of and it often comes down to what services your users are running. If they choose to store data in RMS and query it with Redshift, you will pay more versus if they stored it in Iceberg and query with Athena, for example. Furthermore, if you choose RMS, you’re paying a little more for storage ($0.024 vs. $0.023 for standard S3), and you’re also buying into the pricier RA3 instance type. Choosing Redshift Serverless may be cheaper for some workloads.
Glue Data Catalog storage and APIs, Athena queries, DataZone catalog storage and APIs, Glue crawlers to update metadata in DataZone catalog, Glue and EMR ETL jobs, MWAA workflows, SageMaker Jupyter notebook servers and all of the ML compute services you need for training and inference. THIS IS A LOT!
Unfortunately, resources created by SageMaker aren’t tagged so they are very difficult to find in your Cost Explorer console. This I expect lack of cost and usage transparency will impede adoption of SM-US. Hopefully AWS will solve this soon.
What I would have loved to see is bundled pricing. A model that would allow you to consume resources within SM-US at a standard rate without having to deal with individual service fees. It would make it clear to understand costs and possible to keep them under control.
There is still potential
I don’t want to be too negative. There are a lot of things that simply don’t work or weren’t even considered to SageMaker Unified Studio and SM Lakehouse useful. What’s missing is focus on simplicity and ease of use instead of abundance of choice. Provide reasonable defaults for tools (expose Redshift, leave Athena for advanced users), table formats (settle on Iceberg like the rest of the world), catalog (expose 1 catalog, not 4), etc. will help users get started quickly and will honestly serve >90% of the use cases perfectly well.
If AWS continues to expose more services and more capabilities as they are doing now, without an opinionated way to make them work well together, SM-US will devolve into just another Analytics+AI console in dark-mode. That will not serve them well in this highly competitive market with top-notch alternatives.
Final thoughts
AWS has always been customer obsessed. However, in recent years you can tell, based on product and design choices, that they’ve become a bit more competitor obsessed too. It’s understandable, Snowflake, Databricks and more recently Azure Fabric have been eating away at their analytics customers. Although Snowflake and Databricks run on AWS with a very large investment in compute and storage, the user and ability to up-sale them has been gradually shifting away from AWS native analytics services.
S3 Tables, I believe, is an attempt at capturing back some additional value beyond just storage from those incumbents without forcing users to use AWS analytics services. But as I mentioned in my S3 Tables and the race for managed storage post, the current implementation leaves a lot to be desired and if it continues on this path, it will end up like S3 Select - deprecated.
SageMaker is an important brand for AWS and I think they wanted to leverage its success in AI/ML by combining it with analytics. In theory that’s a smart move. However, as mentioned previously, the execution lacked customer obsession, simplicity and focus on enabling users to combine analytics and AI/ML development to get their jobs done efficiently.
Where should SageMaker Unified Studio go from here? If I was driving, I would pause adding more services (per the first slide - Kinesis, MSK, OpenSearch) and hyper-focus on making data discoverable and accessible for queries, ETL and ML prep and training. Right now that experience is broken, and for SM to be useful it needs to solve for this well. I’ll be prescriptive:
Settle on a single catalog experience (Glue Iceberg-REST) and Iceberg as the default table format.
Default SQL queries and ETL to Redshift serverless - data prep and majority of ETL can be accomplished with only SQL. A bit more expensive, but faster and full-featured letting users get their job done faster.
Offer Glue or EMR for advanced users. Don’t give regular users a choice too early.
Implement a Jupyter SQL magic wired to the same catalog and Redshift serverless for discovering datasets, running queries and including in model training.
Give a single project template/scaffolding that sets all of this up. No jumping between projects.
Tag every resource appropriately so users can easily understand their costs.
Building these products is not easy and this post is not a nock on the AWS folks involved in bringing SM-US to market. Stakeholders, market pressures, revenue goals and technical challenges all influence product decisions and what we first see as the MVP. But first impressions matter a lot, especially in such a fast moving industry with lots of options. Keep up the good work AWS, and please, please prioritize ease of use.
Good luck!
Really good! We've been playing with SM-US over the last few weeks. It was SO HARD to get our first glue table to show up in the UI. And even harder to finally write our first Athena query to it. And now we're playing with the lineage viewer and that's painful, too. I mean... lucky for us, we're doing this so we can write a course on it. And good, I'm glad for our sake that the service is hard... people are gonna need our course!! But no, this is actually just really hard to use rn :/