One Truth, Many Copies: Why Single Source of Truth Isn’t What You Think It Is

One of the main promises of a data warehouse or lakehouse is a single source of truth for all of your data. From this one place, you can transform, enforce high-quality, model and query data. Sounds pretty cool, no?
So why isn’t this the de facto standard?
I recently spoke with a group of engineering and product leaders at a large financial services company and this exact question came up. Their main concern was the disconnect between what’s communicated to the market vs. real-world technical implementations. Sounds familiar?
Rant 🚨: Lets face it, it’s becoming ever more difficult to separate marketing FUD from reality. It’s not just corporate messaging we’re seeing anymore, it’s “influencers” on social media amplifying messages for views, likes and money. There is nothing wrong with this, however it makes it more difficult for engineers and leaders to keep things straight. Often new wanna be influencers trying to build an audience will regurgitate and amplify certain pieces of content without deeply understanding what it is they are sharing. Amplify something for long enough and it will develop a following - for good or bad.
Back to single source of truth (SSOT). There are 3 main ways to slice this problem:
Landing Zone
A single place to store your raw data from which engines can pull, transform and load into purpose built tools or databases, i.e. landing zone. This design pattern is optimized for streaming and real-time data movement and serving. The landing zone is often used as a persistence store for historical data, replay and ML training.
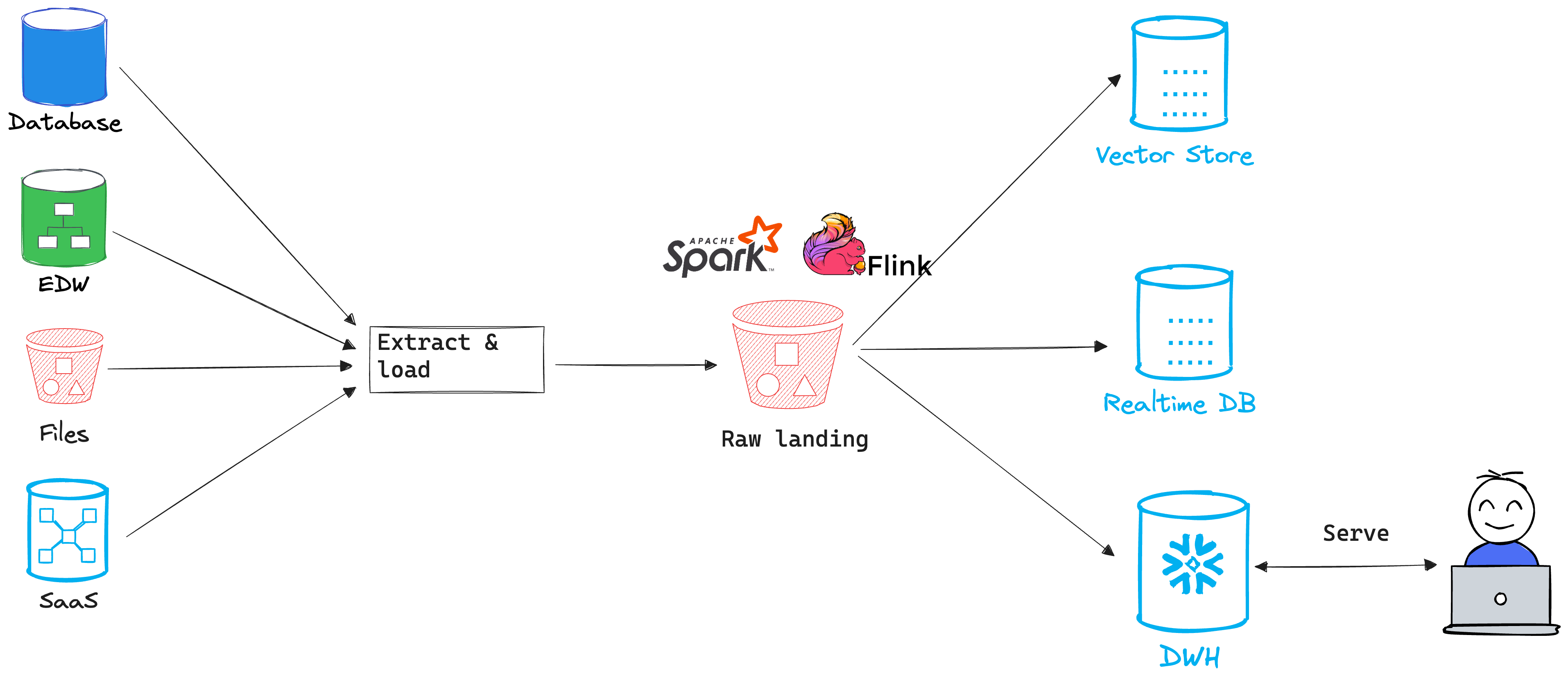
A landing zone pattern allows you to maintain a SSOT for raw data, but doesn’t eliminate the need to make permanent copies of the data in multiple target systems. This is often necessary because data is accessed for low latency use cases like embedded analytics, personalization and AI.
Data engineers are responsible for making sure that target stores are in sync with the SSOT. Business logic transformations, schema evolution and data quality validation are often performed in transit (stream processing) or may sometimes be performed in the landing zone via batch processing. In some situations where the data must be fitted to the target system, like with real-time or vector DBs, transformations will be done after its been loaded, like building indexes or generating vector embeddings. This add complexity since it requires developing and managing important logic in multiple systems.
Warehouse
A single place to store raw and analytics ready data from which a vertically integrated engine can securely access, i.e. data warehouse. This design pattern is optimized for analytics, reporting and BI. More recently, as DWH’s add support for LLMs, this pattern is used to also store documents for GenAI use cases.
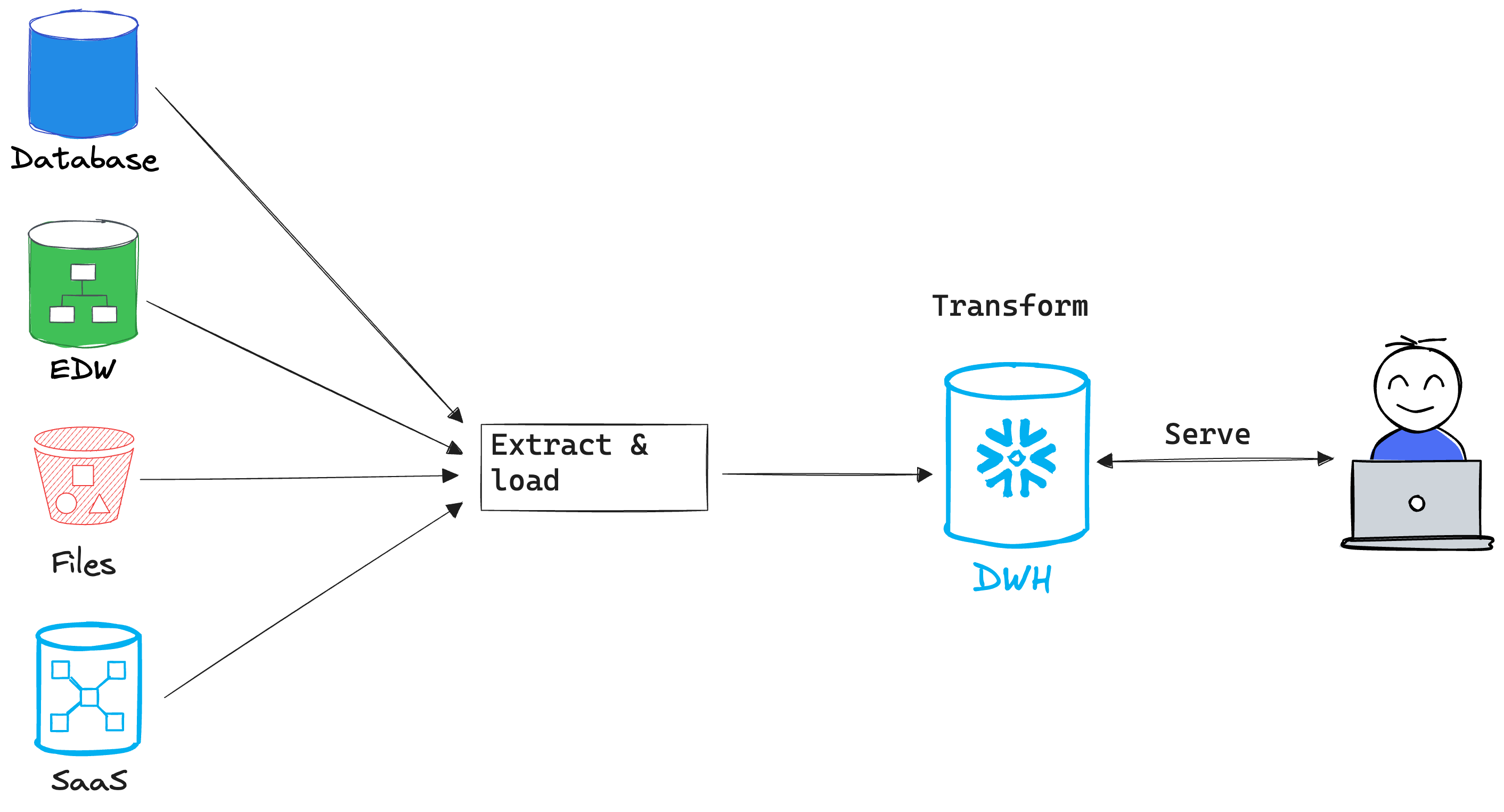
The DWH is a vertically integrated solution that claims to offer everything you need in a single place. It is used to maintain a SSOT for raw, transformed and modeled data. Datasets are used by the DWH for different use cases without making additional copies, unless explicitly requested.
When data is needed for use cases that the DWH can’t support, a physical copy must be made. Unlike the landing zone pattern, making copies of data from the warehouse requires automating export/copy jobs and manually handling incremental changes, schema mapping and evolution, and loading into the target. The challenge with this approach is that moving data from the DWH to a target system doesn’t use well defined interfaces, exposes a technical gap in how performance and scale are handled, and other technical nuances that make the entire process brittle requiring constant hand-holding.
As a SSOT for warehouse-only workloads, this pattern is great, but if you need data to be available for tools outside the warehouse, this pattern is less than ideal.
Lakehouse
A single place to store raw, analytics and AI/ML ready data from which a variety of decoupled, but compatible engines can securely access, i.e. lakehouse. This design pattern is optimized for a wide range of use cases, like real-time, analytics and ML. This pattern can replace both Landing and Warehouse patterns and offer the same benefits without the added fragmentation or duplication of data.
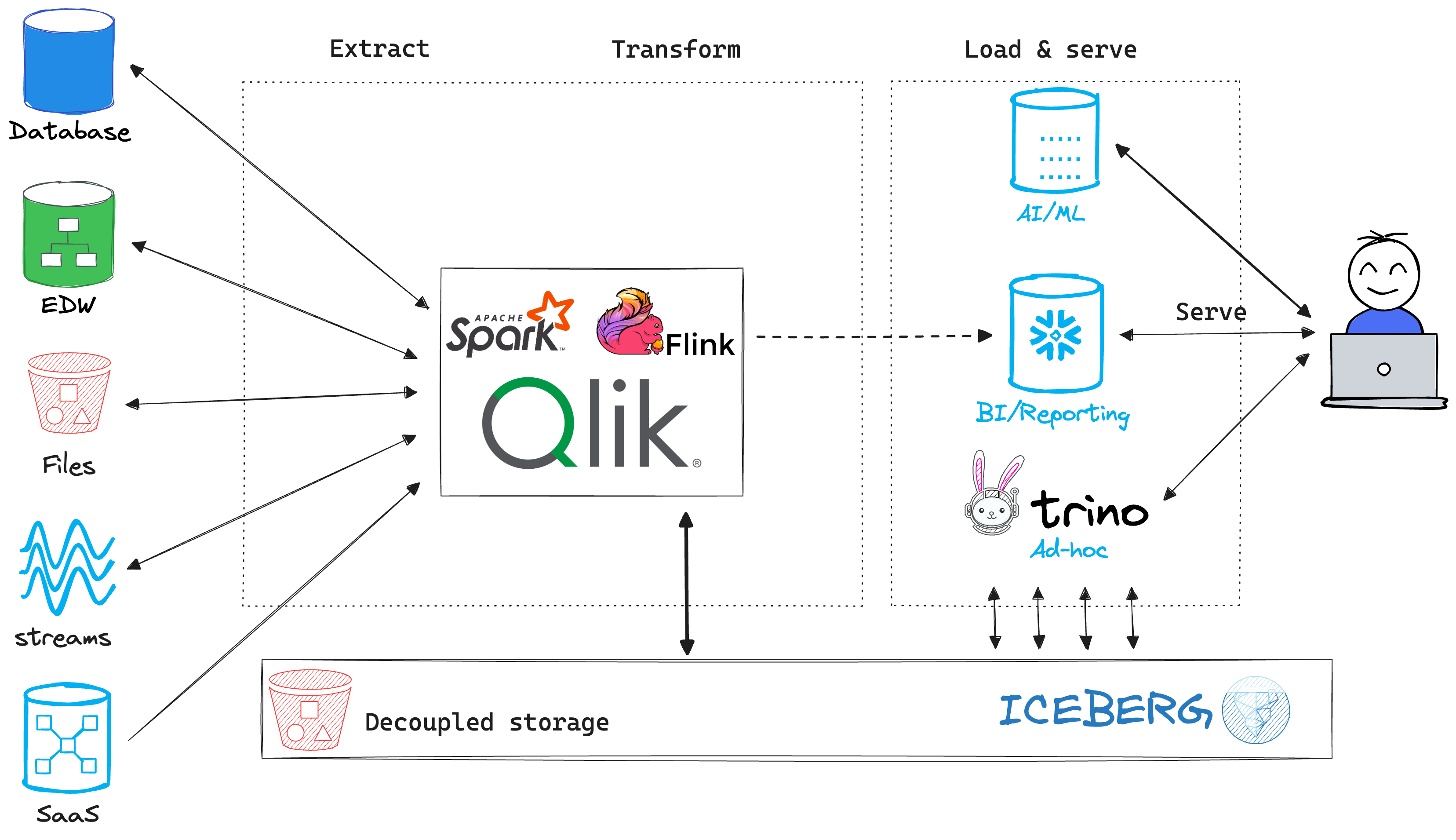
The lakehouse is a decoupled, interoperable architecture that lets you store the data in a single place, commonly using open table format like Apache Iceberg. This makes the data discoverable and accessible from a variety of engines without making copies. The lake becomes the SSOT for raw, transformed and also gold/modeled data.
It’s common, however, to make derived copies of the data to serve use cases that have unique requirements. Often, low latency use cases like serving user-facing applications or inference tasks. You can think of these copies as a cached, temporary representation of the source tables or a subset of them. ETL pipelines keep the cached copies in sync with the SSOT in the lake. These processes are part of the data platform, are built on standard interfaces and are designed to align the source and target behavior to deliver consistent and predictable performance and scale.
SSOT is not without copies
The engineering leader that asked the question was concerned that by positioning a lakehouse as the ideal solution, the expectation is that there will only be one copy of the data. However, many of their use cases require low latency access to data which can’t directly be served from object stores. Data must be cached or even copied into purpose built databases.
Whether you’re making hard copies, symbolic links or caching locally depends on the architecture you choose to implement. A lakehouse architecture enables you to keep and access data in place, without making copies, for majority of your workloads. It also enables you to cache the data in downstream systems without making hard copies (but doesn’t prevent you from doing so) for those workloads that require it. Doing so doesn’t break the SSOT pattern as all caches or copies are synchronized with the source through interoperable interfaces.
Take Snowflake unmanaged Iceberg tables. These Iceberg tables are created in the lake by, lets say, Qlik data integration solution. They are cataloged in Snowflake and automatically refresh when changes are made upstream. You can think of this as a symbolic link. Snowflake will cache some data when query result caching is enabled and automatically keep it in sync with the external Iceberg table.
New engines like StarRocks are already blowing away popular big data engines when it comes to query performance directly accessing Iceberg data in the lake.
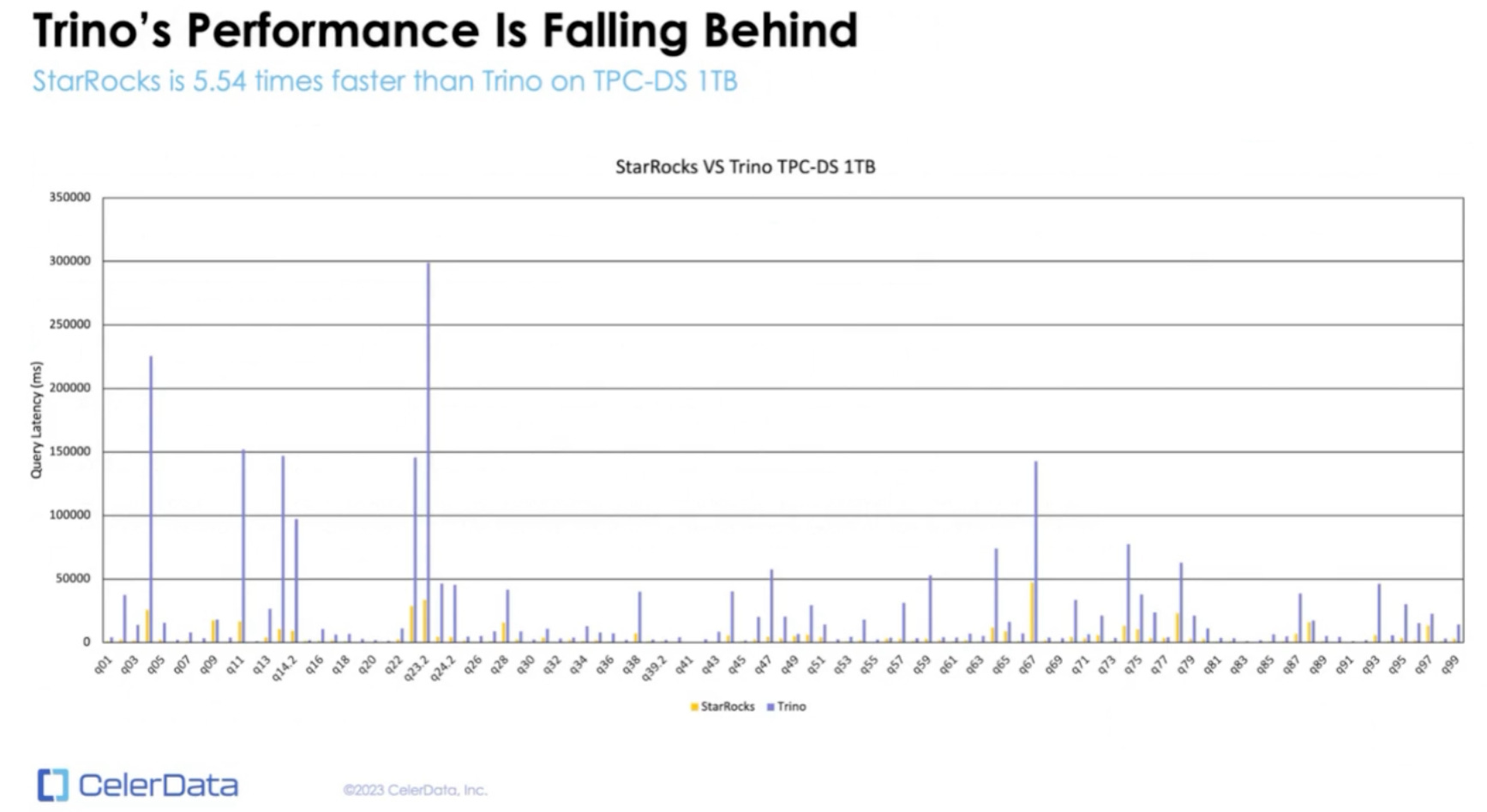
Not all solutions on the market work this way. However, they are getting there. DuckDB, Polars and ClickHouse are quickly adding similar capabilities.
Finally…
Single source of truth gives you a single, trusted place to store, share and access data. Copies are inevitable, but your choice of data architecture will determine how many copies and whether these copies are lightweight and easily maintainable or not.
Plan well, think about where you want to go and focus on decoupled open interfaces and formats.
Good luck!